Depth Anything是什么?
Depth Anything是由来自Tiktok、香港大学和浙江大学的研究人员推出的一个为单目深度估计(Monocular Depth Estimation, MDE)设计的深度学习模型,旨在处理各种情况下的图像并估计其深度信息。该模型的核心特点是利用大规模的未标注数据来增强模型的泛化能力,使其能够在没有人工标注深度信息的情况下,对各种场景的图像进行准确的深度预测。

Depth Anything的官网入口
- 官方项目主页:https://depth-anything.github.io/
- Arxiv研究论文:https://arxiv.org/abs/2401.10891
- GitHub代码库:https://github.com/LiheYoung/Depth-Anything
- Hugging Face Demo:https://huggingface.co/spaces/LiheYoung/Depth-Anything
Depth Anything的主要特点
- 鲁棒性:Depth Anything能够在各种环境条件下,如低光照、复杂场景、雾天和超远距离等情况下,提供准确的深度估计。
- 零样本学习:模型能够在没有特定数据集训练的情况下,对未见过的图像进行深度估计,具有很强的泛化能力。
- 数据增强:通过使用数据增强工具,如颜色抖动和高斯模糊,以及CutMix等空间扰动,模型能够在训练过程中学习到更丰富的视觉知识,从而提高其对未知图像的处理能力。
- 语义辅助感知:Depth Anything利用预训练的编码器(如DINOv2)来提供丰富的语义信息,这有助于模型更好地理解场景内容,从而提高深度估计的准确性。
- 多任务学习:模型不仅能够进行深度估计,还能够在多任务学习框架下进行语义分割,这表明它有潜力成为一个通用的多任务编码器,适用于中层和高层的视觉感知任务。
Depth Anything的工作原理
Depth Anything的工作原理基于深度学习和大规模数据集的结合,特别是利用未标注数据来增强模型的泛化能力。
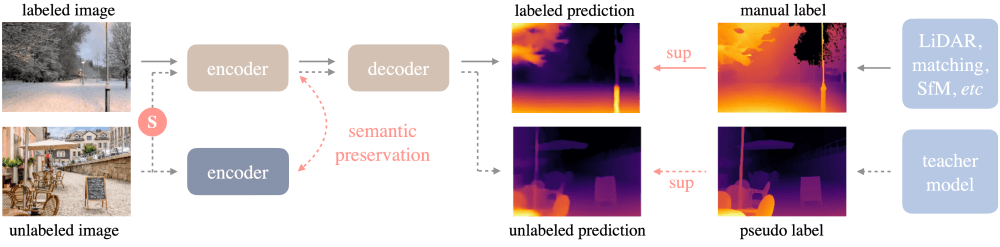
以下是其工作原理的关键步骤:
- 数据收集与预处理:
- 首先,研究者们设计了一个数据引擎,用于从多个公共大型数据集中收集原始未标注的图像,这些图像覆盖了广泛的多样性,如不同的场景、光照条件和天气状况。
- 然后,使用预训练的单目深度估计(MDE)模型对这些未标注图像进行深度预测,生成伪标签(pseudo labels),这些伪标签将用于后续的训练过程。
- 模型训练:
- 在第一阶段,使用从公共数据集中收集的标注图像训练一个教师模型(teacher model),这个模型将作为后续学生模型(student model)的基础。
- 在第二阶段,学生模型在教师模型的帮助下,结合标注图像和伪标签图像进行联合训练。这一过程称为自训练(self-training)。
- 数据增强与挑战:
- 为了提高模型的鲁棒性,研究者们在未标注图像上应用了强扰动,如颜色失真和空间剪切(CutMix),迫使模型在训练过程中学习到更鲁棒的表示。
- 语义辅助:
- 为了增强模型的场景理解能力,研究者们采用了辅助特征对齐损失(feature alignment loss),使得学生模型在特征空间中与预训练的语义分割模型(如DINOv2)保持一致。这有助于模型在深度估计任务中更好地理解场景内容。
- 模型微调和评估:
- 在训练完成后,Depth Anything模型可以通过微调来适应特定的深度估计任务,如使用NYUv2和KITTI数据集的度量深度信息进行微调,以进一步提高其在特定任务上的性能。
Depth Anything的应用场景
- 机器人导航:在机器人领域,准确的深度信息对于机器人理解周围环境、规划路径和避免障碍物至关重要。Depth Anything可以帮助机器人在复杂或未知的环境中进行有效的导航。
- 自动驾驶:自动驾驶系统需要精确的深度信息来识别道路、车辆、行人和其他障碍物,以确保安全驾驶。Depth Anything可以提供这些关键信息,增强自动驾驶车辆的环境感知能力。
- 增强现实(AR)和虚拟现实(VR):在AR和VR应用中,Depth Anything可以用来估计现实世界中的深度信息,从而实现更自然和逼真的虚拟对象与现实世界的融合。
- 3D重建:通过单目图像估计深度,Depth Anything可以辅助3D建模和重建,为建筑、城市规划、文化遗产保护等领域提供支持。
- 游戏开发:在游戏开发中,Depth Anything可以用来增强游戏的视觉效果,通过估计场景深度来实现更真实的光影效果和景深效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。