UniEdit是什么
UniEdit是由浙江大学、微软研究院和北京大学的研究人员推出的一个创新的视频编辑框架,允许用户在不需要进行模型微调的情况下,对视频的运动和外观进行编辑。该框架的核心优势在于能够同时处理视频的时间维度(如动作变化)和空间维度(如风格化、物体替换、背景修改)的编辑任务。

UniEdit的官网入口
- 官方项目主页:https://jianhongbai.github.io/UniEdit/
- arXiv研究论文:https://arxiv.org/abs/2402.13185
- GitHub代码库:https://github.com/JianhongBai/UniEdit(源代码待上线)
UniEdit的功能特性
- 视频对象动作编辑:UniEdit能够根据文本指令编辑视频中对象的动作。例如,可以将视频中的浣熊弹吉他的动作编辑成吃苹果或招手的动作。
- 视频风格化:该框架支持对视频进行风格迁移,即用户可以通过文本描述来改变视频的视觉风格,而不需要改变视频中的内容,如将视频转换为油画风格。
- 视频背景修改:UniEdit允许用户修改更换视频中的背景。例如,可以将视频中的人物置于完全不同的场景中。
- 视频对象物体替换:UniEdit框架支持刚性和非刚性物体的替换,用户可以替换视频中的静态或动态物体,
- 无需训练微调:UniEdit不需要额外的训练或微调,大大简化了模型的部署和使用,使得用户可以快速上手进行视频编辑。
UniEdit的工作原理
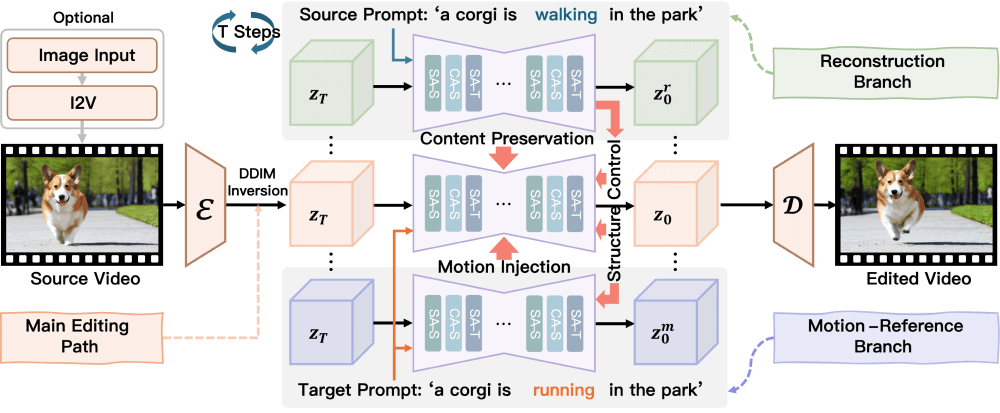
- 反演处理(Inversion):UniEdit首先对输入的视频进行反演处理,将其转换为一个随机噪声表示。这个过程通常涉及到使用预训练的扩散视频生成模型(如 LaVie)的反演过程,通过一系列去噪步骤将视频逐步从噪声状态转换回其原始状态。
- 生成编辑路径:在反演处理的基础上,UniEdit 使用预训练的 UNet 模型进行去噪步骤,以生成编辑后的视频。该过程是在给定目标文本提示的条件下进行的,以确保生成的视频内容符合用户的编辑意图。
- 辅助重建分支:为了保留源视频的非编辑内容,UniEdit 引入了一个辅助重建分支。这个分支从相同的逆向噪声开始,但在给定源视频文本提示的条件下进行去噪,以重建原始视频帧。重建过程中的特征被注入到主编辑路径的空间自注意力层中,以保持内容的一致性。
- 辅助运动参考分支:为了实现运动/动作编辑,UniEdit 引入了辅助运动参考分支,在给定目标文本提示的条件下生成运动特征。这些特征通过时间自注意力层注入到主编辑路径中,以引导视频的运动变化。
- 内容保留与运动注入:在主编辑路径中,UniEdit 通过替换空间自注意力层的值特征来保留源视频的内容。同时,通过在时间自注意力层中注入运动特征,实现运动的编辑。
- 空间结构控制:在外观编辑中,UniEdit 通过替换主编辑路径中的空间自注意力层的查询和键特征,来保持源视频的空间结构。这有助于在改变视频风格或外观时,保持物体的布局和位置不变。
- 文本引导编辑:用户通过提供文本描述来指导视频编辑过程。UniEdit 解析这些文本描述,并将其转化为视频编辑的指导信号,从而实现用户期望的编辑效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。