AnimateDiff是什么?
AnimateDiff是由上海人工智能实验室、香港中文大学和斯坦福大学的研究人员推出的一款将个性化的文本到图像模型扩展为动画生成器的框架,其核心在于它能够利用从大规模视频数据集中学习到的运动先验知识,可以作为 Stable Diffusion 文生图模型的插件,允许用户将静态图像转换为动态动画。该框架的目的是简化动画生成的过程,使得用户能够通过文本描述来控制动画的内容和风格,而无需进行特定的模型调优。
AnimateDiff的官网入口
- 官方项目主页:https://animatediff.github.io/
- Arxiv研究论文:https://arxiv.org/abs/2307.04725
- GitHub代码库:https://github.com/guoyww/animatediff/
- Hugging Face Demo:https://huggingface.co/spaces/guoyww/AnimateDiff
- OpenXLab Demo:https://openxlab.org.cn/apps/detail/Masbfca/AnimateDiff
AnimateDiff的功能特色
- 个性化动画生成:AnimateDiff允许用户将个性化的文本到图像模型(如Stable Diffusion)转化为动画生成器。这意味着用户可以输入文本描述,模型不仅能够生成静态图像,还能生成与文本描述相符的动画序列。
- 无需模型特定调整:AnimateDiff的核心优势在于它不需要对个性化模型进行额外的调整。用户可以直接使用框架中预训练的运动建模模块,将其插入到个性化T2I模型中,实现动画生成。
- 保持风格特性:在生成动画的过程中,AnimateDiff能够保持个性化模型的领域特性,确保生成的动画内容与用户定制的风格和主题保持一致。
- 跨领域应用:AnimateDiff支持多种领域的个性化模型,包括动漫、2D卡通、3D动画和现实摄影等,使得用户可以在不同风格和主题之间自由切换,创作多样化的动画内容。
- 易于集成:AnimateDiff的设计使得它易于与现有的个性化T2I模型集成,用户无需具备深厚的技术背景即可使用,大大降低了使用门槛。
AnimateDiff的工作原理
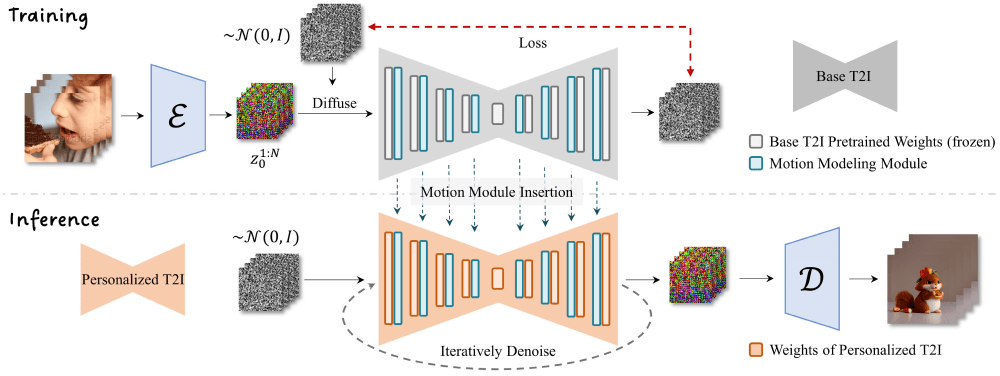
- 运动建模模块的插入:首先,AnimateDiff在现有的文本到图像模型中插入一个专门设计的运动建模模块。这个模块负责理解和生成动画中的运动信息,它被设计为能够在模型的不同分辨率层次上工作,以确保生成的动画在细节上保持一致性。
- 视频数据训练:运动建模模块通过在大规模视频数据集上进行训练,学习视频中的运动模式。这个训练过程是在模型的冻结状态下进行的,即基础T2I模型的参数保持不变,以避免影响其原有的图像生成能力。
- 时间维度的注意力机制:AnimateDiff使用标准的注意力机制(如Transformer中的自注意力)来处理时间维度。这种机制允许模型在生成动画的每一帧时,都能够考虑到前一帧和后一帧的信息,从而实现平滑的过渡和连贯的动作。
- 动画生成:待运动建模模块训练完成,它就可以被插入到任何基于同一基础文生图模型的个性化模型中。在生成动画时,用户输入文本描述,模型会结合文本内容和运动建模模块学习到的运动先验知识,生成与文本描述相符的动画序列。
© 版权声明
文章版权归作者所有,未经允许请勿转载。