Hyper-SD是什么
Hyper-SD是由字节跳动的研究人员推出的一个高效的图像合成框架,旨在解决现有扩散模型在多步推理过程中计算成本高昂的问题。Hyper-SD通过轨迹分割一致性蒸馏(TSCD)技术,在不同时间段内保持数据的一致性,从而有效保留了原始的ODE(常微分方程)轨迹。此外,它还融入了人类反馈学习,优化了在低步数推理情况下的模型性能,并利用分数蒸馏进一步提升了单步推理的图像质量。该框架能够在保持高图像质量的同时,大幅减少必要的推理步骤,实现快速生成高分辨率图像,进一步推动了生成AI领域的发展。
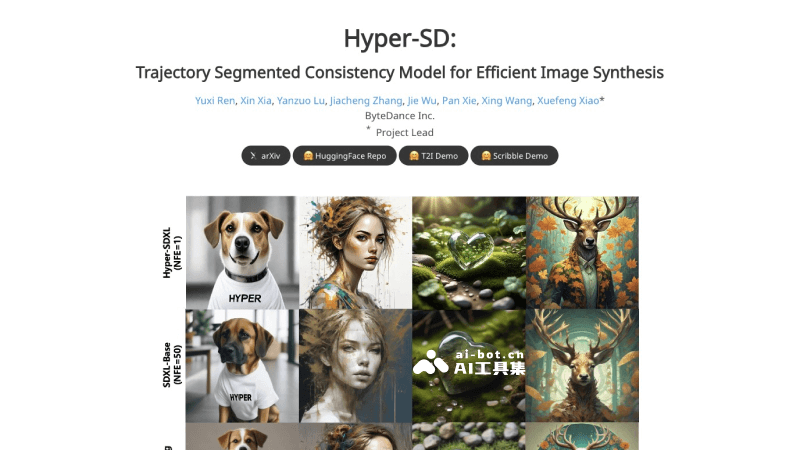
Hyper-SD的官网入口
- 官方项目主页:https://hyper-sd.github.io/
- Hugging Face模型地址:https://huggingface.co/ByteDance/Hyper-SD
- arXiv研究论文:https://arxiv.org/abs/2404.13686
- Hyper-SD T2I版Demo:https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
- Hyper-SD 涂鸦版Demo:https://huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble
Hyper-SD的工作原理
- 轨迹分割一致性蒸馏(TSCD):将训练时间步长范围[0, T]划分为k个均匀的时间段。在每个时间段内部执行一致性蒸馏,使用原始模型作为教师,学生模型逐步学习教师模型的行为。通过逐步减少时间段的数量(如8 → 4 → 2 → 1),训练学生模型以逼近教师模型的全局行为。
- 人类反馈学习(ReFL):利用人类对图像的偏好反馈来优化模型。训练奖励模型,使其能够识别并奖励更符合人类审美的图像。通过迭代去噪和直接预测,结合奖励模型的反馈,微调学生模型。
- 分数蒸馏:使用真实分布和假分布的得分函数来指导单步推理过程。通过最小化两个分布之间的KL散度,优化学生的单步生成性能。
- 低秩适应(LoRA):使用LoRA技术来适配和训练学生模型,使其成为一个轻量级的插件,可以快速部署和使用。
- 训练和损失函数优化:定义损失函数,结合一致性损失、人类反馈损失和分数蒸馏损失。使用梯度下降等优化算法来训练学生模型,同时更新LoRA插件。
- 推理和图像生成:在训练完成后,使用学生模型进行图像生成的推理过程。根据应用场景的需求,选择适当的推理步骤数量,以平衡生成质量和效率。
- 性能评估:使用定量指标(如CLIP分数、美学分数)和定性指标(如用户研究)来评估生成图像的质量。根据评估结果,进一步调整和优化模型参数。
© 版权声明
文章版权归作者所有,未经允许请勿转载。