Open-Sora是什么
Open-Sora是由Colossal-AI团队开源的视频生成模型,旨在复现OpenAI的Sora视频生成产品。Open-Sora同样基于DiT架构,通过三个阶段训练:大规模图像预训练、大规模视频预训练和高质量视频数据微调,以生成与文本描述相符的视频内容。该开源解决方案涵盖了整个视频生成模型的训练过程,包括数据处理、所有训练细节和模型检查点,供所有对文生视频模型感兴趣的人免费学习和使用。

Open-Sora的官网入口
Open-Sora的模型架构
Open-Sora模型采用当前流行的Diffusion Transformer(DiT)架构,使用华为开源的PixArt-α高质量文本到图像生成模型,并通过添加时间注意力层将其扩展为生成视频。具体设计如下:
核心组件
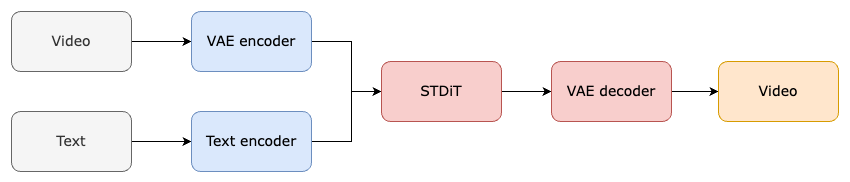
- 预训练的VAE (变分自编码器):VAE是用于数据压缩的组件,它将输入的视频数据映射到一个潜在空间的低维表示。在Open-Sora中,VAE的编码器部分在训练阶段用于压缩视频数据,而在推理阶段,它从潜在空间中采样高斯噪声并生成视频。
- 文本编码器:这个组件负责将文本提示(如描述视频内容的句子)转换为文本嵌入,这些嵌入随后与视频数据结合,以确保生成的视频符合文本描述。
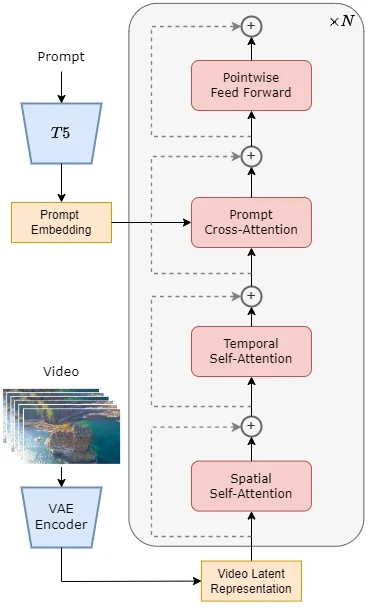
- STDiT (Spatial Temporal Diffusion Transformer):这是Open-Sora的核心组件,一个利用空间-时间注意力机制的DiT模型。STDiT通过串行地在二维空间注意力模块上叠加一维时间注意力模块来建模视频数据中的时序关系。此外,交叉注意力模块用于对齐文本的语义信息。
架构设计
- 空间-时间注意力机制:STDiT模型的每一层都包含空间注意力模块和时间注意力模块。空间注意力模块处理视频帧的二维空间特征,而时间注意力模块则处理帧之间的时序关系。这种设计使得模型能够有效地处理视频数据中的空间和时间维度。
- 交叉注意力:在时间注意力模块之后,交叉注意力模块用于将文本嵌入与视频特征融合,确保生成的视频内容与文本描述相匹配。
- 训练与推理流程:在训练阶段,VAE的编码器将视频数据压缩,然后与文本嵌入一起用于训练STDiT模型。在推理阶段,从VAE的潜在空间中采样出噪声,与文本提示一起输入到STDiT模型中,生成去噪后的特征,最后通过VAE的解码器解码得到最终的视频。

Open-Sora的复现方案
Open-Sora的训练复现方案参考了Stable Video Diffusion (SVD)的工作,分为三个阶段:大规模图像预训练、大规模视频预训练和高质量视频数据微调。通过这三个阶段的训练复现方案,Open-Sora模型能够逐步提升其视频生成的能力,从基础的图像理解到复杂的视频内容生成,最终达到高质量的视频生成效果。
第一阶段:大规模图像预训练
在第一阶段,模型通过大规模图像数据集进行预训练,以建立对图像内容的基本理解。这个阶段的目的是利用现有的高质量图像生成模型(如Stable Diffusion)作为基础,来初始化视频生成模型的权重。通过这种方式,模型能够从图像数据中学习到丰富的视觉特征,为后续的视频预训练打下坚实的基础。
第二阶段:大规模视频预训练
第二阶段专注于大规模视频数据的预训练,目的是增强模型对视频时间序列的理解。在这个阶段,模型通过大量的视频数据进行训练,以学习视频中的时序关系和动态变化。为了提高模型的泛化能力,需要确保视频题材的多样性。此外,模型在这个阶段会加入时序注意力模块,以更好地处理时间序列数据。这个阶段的训练会在第一阶段的基础上进行,使用前一阶段的权重作为起点。
第三阶段:高质量视频数据微调
最后一个阶段是对模型进行微调,使用高质量的视频数据来进一步提升生成视频的质量和真实感。在这个阶段,虽然使用的视频数据量可能比第二阶段少,但视频的时长、分辨率和质量都会更高。微调过程有助于模型捕捉到更加细致和逼真的视频内容,从而生成更加符合用户期望的视频。