混元DiT是什么
混元DiT(Hunyuan-DiT)是由腾讯混元团队开源的一款高性能的文本到图像的扩散Transformer模型,具备细粒度的中英文理解能力,能够根据文本提示生成多分辨率的高质量图像。混元DiT采用了创新的网络架构,结合了双语CLIP和多语言T5编码器,通过精心设计的数据管道进行训练和优化,支持多轮对话,能够根据上下文生成并完善图像。在中文到图像生成领域,混元DiT达到了开源模型中的领先水平。

混元DiT的主要功能
- 双语文本到图像生成:混元DiT能够根据中文或英文的文本提示生成图像,这使得它在跨语言的图像生成任务中具有广泛的应用潜力。
- 细粒度中文元素理解:模型特别针对中文进行了优化,可以更好地理解和生成与中国传统文化相关的元素,如中国古诗、中国传统服饰、中国节日等。
- 长文本处理能力:支持长达256个标记的文本输入,使得DiT能够理解和生成与复杂长文本描述相匹配的图像。
- 多尺寸图像生成:Hunyuan-DiT能够在多种尺寸比例下生成高质量的图像,满足从社交媒体帖子到大尺寸打印等不同用途的需求。
- 多轮对话和上下文理解:通过与用户进行多轮对话,混元DiT能够根据对话历史和上下文信息生成和迭代图像,这增强了交互性和创造性。
- 图像与文本的高一致性:Hunyuan-DiT生成的图像在内容上与输入的文本提示高度一致,确保了图像能够准确反映文本的意图和细节。
- 艺术性和创意性:混元DiT不仅能够生成常见的图像,还能够捕捉文本中的创意描述,生成具有艺术性和创意性的图像作品。

混元DiT的官网入口
- 官方项目主页:https://dit.hunyuan.tencent.com/
- Hugging Face模型:https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
- GitHub源码:https://github.com/Tencent/HunyuanDiT
- 技术报告:https://tencent.github.io/HunyuanDiT/asset/Hunyuan_DiT_Tech_Report_05140553.pdf
混元DiT的技术架构
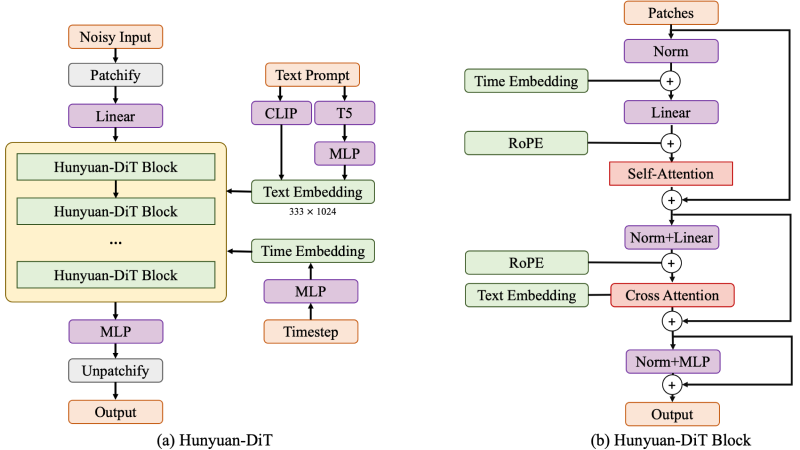
- 双文本编码器:混元DiT结合了双语CLIP和多语言T5编码器,以增强对输入文本的理解和编码能力。CLIP模型因其强大的图像和文本之间的关联能力而被选用,而T5模型则因其在多语言和文本理解方面的能力。
- 变分自编码器(VAE):使用预训练的VAE将图像压缩到低维潜在空间,这有助于扩散模型学习数据分布。VAE的潜在空间对生成质量有重要影响。
- 扩散模型:基于扩散Transformer,混元DiT使用扩散模型来学习数据分布。该模型通过交叉注意力机制将文本条件与扩散模型结合。
- 改进的生成器:扩散Transformer相比于基线DiT有若干改进,例如使用自适应层归一化(AdaNorm)来加强细粒度文本条件的执行。
- 位置编码:混元DiT采用旋转位置嵌入(RoPE)来同时编码绝对位置和相对位置依赖性,支持多分辨率训练和推理。
- 多模态大型语言模型(MLLM):用于图像-文本对的原始标题的重构,以提高数据质量。MLLM经过微调,能够生成包含世界知识的结构化标题。
- 数据管道:包括数据获取、解释、分层和应用。通过一个称为“数据车队”的迭代过程来检查新数据的有效性。
- 后训练优化:在推理阶段进行优化,以降低部署成本,包括ONNX图优化、内核优化、操作融合等。
混元DiT与其他文生图模型的比较
为了全面比较HunyuanDiT与其他模型的生成能力,混元团队构建了4个维度的测试集,超过50名专业评估人员进行评估,包括文本图像一致性、排除AI伪影、主题清晰度、审美。
| 模型 | 开源 | 文图一致性(%) | 排除 AI 伪影(%) | 主题清晰度(%) | 审美(%) | 综合得分(%) |
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 |
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 |
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 |
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 |
| Midjourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 |
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 |
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。