OLMo是什么?
OLMo(Open Language Model)是由Allen AI(AI2,艾伦人工智能研究所)开发的一个完全开源开放的大型语言模型(LLM)框架,设计初衷是为了通过开放研究,促进学术界和研究人员共同研究语言模型的科学。OLMo框架提供了一系列的资源,包括数据、训练代码、模型权重以及评估工具,以便研究人员能够更深入地理解和改进语言模型。

OLMo的官网入口
- 官方项目主页:https://allenai.org/olmo
- GitHub代码库:https://github.com/allenai/olmo
- Hugging Face地址:https://huggingface.co/allenai/OLMo-7B
- 研究论文:https://allenai.org/olmo/olmo-paper.pdf
OLMo的主要特点
- 大规模预训练数据:基于AI2的Dolma数据集,这是一个包含3万亿个标记的大规模开放语料库,为模型提供了丰富的语言学习材料。
- 多样化的模型变体:OLMo框架包含了四种不同规模的模型变体,每种模型至少经过2万亿token的训练,这为研究人员提供了多种选择,以适应不同的研究需求。
- 详细的训练和评估资源:除了模型权重,OLMo还提供了完整的训练日志、训练指标和500多个检查点,这些资源可以帮助研究人员更好地理解模型的训练过程和性能。
- 开放性和透明度:OLMo的所有代码、权重和中间检查点都在Apache 2.0许可证下发布,这意味着研究人员可以自由地使用、修改和分发这些资源,以促进知识的共享和创新。
OLMo的模型性能
据OLMo的论文报告,OLMo-7B模型在零样本(zero-shot)评估中的表现与其他几个模型进行了对比,这些模型包括Falcon-7B、LLaMA-7B、MPT-7B、Pythia-6.9B、RPJ-INCITE-7B和LLaMA-7B。
以下是OLMo-7B在一些核心任务上的比较结果:
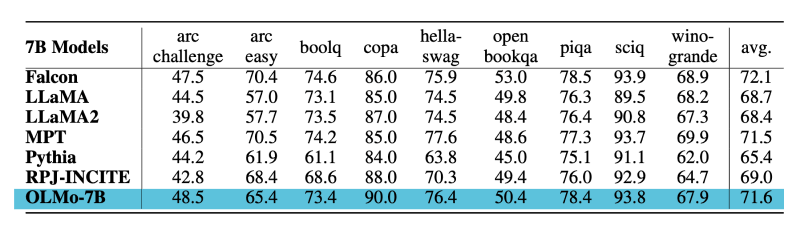
- 下游任务评估:OLMo-7B在9个核心任务的零样本评估中,在2个任务(科学问题和因果推理)上表现最佳,8个任务上保持在前三名。这表明OLMo-7B在这些任务上具有较强的竞争力。
- 基于困惑度的评估:在Paloma评估框架中,OLMo-7B在多个数据源上的困惑度(bits per byte)表现也显示出竞争力。特别是在与代码相关的数据源(如Dolma 100 Programming Languages)上,OLMo-7B的表现显著优于其他模型。
- 额外任务评估:在额外的6个任务(headqa en、logiqa、mrpcw、qnli、wic、wnli)上,OLMo-7B在零样本评估中的表现同样优于或接近其他模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。