DiffusionGPT是什么?
DiffusionGPT是由来自字节跳动与中山大学的研究人员推出的一个开源的大模型(LLM)驱动的文本到图像生成系统,旨在解决文生图领域无法处理不同的输入或者仅限于单一模型结果的挑战。该系统利用思维树和优势数据库的技术能够处理多种类型的文本提示,并将这些提示与领域专家模型相结合,以生成高质量的图像。

DiffusionGPT的官网入口
- 官方项目主页:https://diffusiongpt.github.io/
- Arxiv研究论文:https://arxiv.org/abs/2401.10061
- GitHub代码库:https://github.com/DiffusionGPT/DiffusionGPT
- Hugging Face运行地址:https://huggingface.co/spaces/DiffusionGPT/DiffusionGPT
- DiffusionGPT-XL Demo:https://huggingface.co/spaces/DiffusionGPT/DiffusionGPT-XL
DiffusionGPT的主要特点
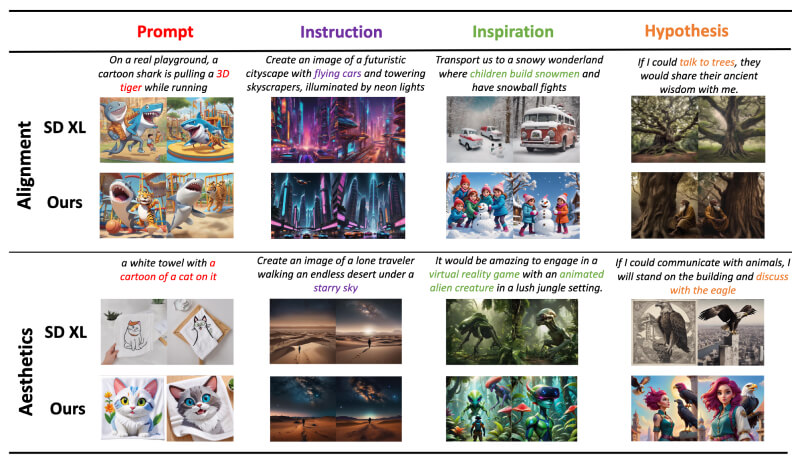
- 文本提示解析:DiffusionGPT能够理解和解析各种类型的文本提示,包括基于描述的、基于指令的、基于启发的和基于假设的提示。这一功能使得系统能够准确把握用户想要生成的图像内容。
- 模型选择与集成:系统通过构建一个基于思维树(Tree-of-Thought, ToT)的结构,将多个领域专家生成模型进行分类和组织。这允许DiffusionGPT根据输入的文本提示,从众多模型中选择最合适的一个来生成图像。
- 人类反馈优化:DiffusionGPT利用人类反馈来优化模型选择过程。通过优势数据库(Advantage Databases),系统可以根据人类对模型生成结果的评分来选择表现最佳的模型,从而提高生成图像的质量和用户满意度。
- 图像生成执行:在选择了合适的模型后,DiffusionGPT会执行图像生成过程。为了增强生成图像的细节和艺术性,系统还会通过提示扩展代理来丰富和细化输入提示。
- 多领域适用性:DiffusionGPT设计为一个全能系统,不仅适用于描述性文本提示,还能够处理更复杂的指令和启发性内容,这使得它在多样化的应用场景中具有广泛的适用性。
- 即插即用解决方案:DiffusionGPT的设计使其成为一个训练免费、易于集成的解决方案,可以轻松地集成到现有的图像生成流程中,为用户提供便捷的服务。
DiffusionGPT的工作原理
DiffusionGPT的工作原理可以分为四个主要步骤,这些步骤共同协作以实现从文本提示到高质量图像生成的过程:
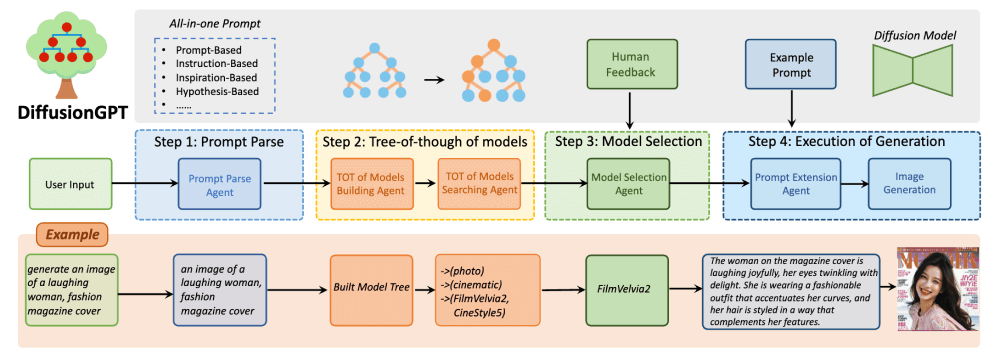
- 提示解析(Prompt Parse):
- DiffusionGPT首先使用大语言模型(LLM)来分析和提取输入文本提示中的关键信息。这个过程对于生成用户期望的内容至关重要,因为用户输入可能包含多种类型的提示,如基于描述的、基于指令的、基于启发的或基于假设的。
- LLM能够识别这些提示的不同形式,并提取出核心内容,以便为后续的图像生成提供准确的指导。
- 模型构建和搜索的思维树(Tree-of-Thought of Models):
- 在解析了提示之后,系统会构建一个基于思维树(ToT)的结构,这个结构包含了多个领域专家生成模型。这些模型根据它们的属性被分类到不同的节点,形成一个层次化的结构。
- 通过这个思维树,系统可以缩小候选模型的范围,提高模型选择的准确性。这个过程类似于在树中搜索,从根节点开始,根据提示内容逐步向下寻找最匹配的模型。
- 模型选择(Model Selection):
- 在确定了候选模型集之后,DiffusionGPT会利用人类反馈和优势数据库(Advantage Databases)来选择最合适的模型。这个数据库包含了对模型生成结果的评分,基于这些评分,系统可以确定哪些模型在处理特定类型的提示时表现最佳。
- 系统会根据输入提示与数据库中的提示进行语义相似度计算,然后选择与这些提示最匹配的模型,以确保生成的图像符合用户的期望。
- 生成执行(Execution of Generation):
- 最后,选定的模型会根据提取的核心提示生成图像。为了提高生成图像的质量,DiffusionGPT还会使用提示扩展代理(Prompt Extension Agent)来丰富和细化输入提示,使其更加详细和具有描述性。
- 这样,生成的图像不仅能够捕捉到提示的核心内容,还能展现出更高的细节和艺术性。
通过这四个步骤,DiffusionGPT能够无缝地处理多样化的文本提示,并生成与用户意图高度一致的高质量图像。这个系统的设计旨在提高图像生成的灵活性和效率,同时利用人类反馈来不断优化生成过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。