AtomoVideo是什么
AtomoVideo是由阿里巴巴的研究团队提出的一个高保真图像到视频(Image-to-Video, I2V)生成框架,旨在从输入的静态图像生成高质量的视频内容。该框架基于多粒度图像注入和高质量的数据集及训练策略,使其能够保持生成视频与给定参考图像之间的高保真度,同时实现丰富的运动强度和良好的时间一致性。
相较于Runway Gen-2和Pika 1.0,AtomoVideo在保持图像细节、生成动态视频以及提供个性化和可控生成方面表现出了一定的优势。

AtomoVideo的官网入口
- 官方项目主页:https://atomo-video.github.io/
- arXiv研究论文:https://arxiv.org/abs/2403.01800
AtomoVideo的功能特性
- 高保真图像到视频生成:AtomoVideo能够根据用户输入的静态图像生成与之高度一致的视频内容,生成的视频在风格、内容和细节上都与原始图像保持高度相似。
- 视频帧预测:该框架支持长视频序列的生成,通过迭代预测后续帧的方式,可以从一系列初始帧生成更长的视频内容。
- 时间一致性和稳定性:AtomoVideo在生成视频时,注重时间上的连贯性和稳定性,确保视频播放时动作流畅,不会出现突兀的跳转或不连贯的画面。
- 文本到视频生成:结合先进的文本到图像模型,AtomoVideo还能够实现文本到视频的生成,用户可以通过文本描述来指导视频内容的创作。
- 个性化和可控生成:通过与个性化的文生图模型和可控生成模型的结合,AtomoVideo能够根据用户的特定需求生成定制化的视频内容。
AtomoVideo的工作原理
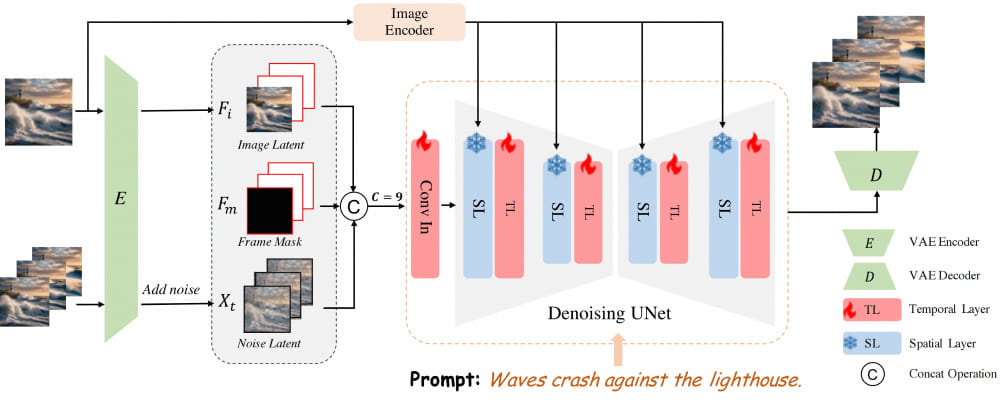
- 整体流程:AtomoVideo 使用预训练的文本到图像(T2I)模型作为基础,并在每个空间卷积和注意力层之后添加新的一维时间卷积和时间注意力模块。在训练过程中,只有添加的时间层和输入层的参数会被更新,而T2I模型的参数保持固定。
- 图像信息注入:为了在生成视频中保持与输入图像的一致性,AtomoVideo 在两个不同的位置上注入图像信息。首先,通过VAE编码器将输入图像编码为低级表示,然后将其与高斯噪声结合。同时,使用CLIP图像编码器提取图像的高级语义表示,并通过交叉注意力层注入到生成过程中。

- 视频帧预测:为了实现长视频的生成,AtomoVideo采用迭代预测的方法。给定一系列初始视频帧,模型会预测接下来的帧。这种方法允许在有限的GPU内存约束下生成长视频序列。
- 训练和推理:在训练阶段,AtomoVideo使用内部的15M数据集,其中每个视频大约10-30秒长,并且视频的文本描述也被输入到模型中。训练过程中采用了零终端信噪比(SNR)和v-prediction策略,以提高视频生成的稳定性。模型的输入尺寸为512×512,包含24帧。在推理阶段,模型执行分类器自由引导(Classifier-Free Guidance),结合图像和文本条件注入,以提高生成输出的稳定性。
- 个性化视频生成:AtomoVideo在训练时固定了基础2D UNet的参数,只训练添加的参数,因此可以与社区中流行的个性化模型结合。例如,可以与epiCRealism这样的T2I模型结合,该模型擅长生成光和影效果,用于I2V生成时倾向于生成包含光元素的视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。