VideoCrafter2 是什么?
VideoCrafter2是一个由腾讯AI实验室开发的视频生成模型,旨在克服高质量视频数据获取的局限性,训练出能够生成高质量视频的模型。该模型的核心思想是将视频的生成过程分解为两个主要部分:运动(motion)和外观(appearance)。通过这种方法,VideoCrafter2 能够在没有高质量视频数据的情况下,利用低质量视频来保证运动的一致性,同时使用高质量的图像来确保生成视频的画面质量和概念组合能力。
项目主页:https://ailab-cvc.github.io/videocrafter2/
论文地址:https://arxiv.org/abs/2401.09047
GitHub代码库:https://github.com/AILab-CVC/VideoCrafter
Hugging Face Demo:https://huggingface.co/spaces/VideoCrafter/VideoCrafter2
VideoCrafter2 的功能特色
- 文本到视频的转换:用户可以提供一段描述性的文本,VideoCrafter2 即可根据这段文本生成相应的视频
- 高质量视频生成:VideoCrafter2 能够生成具有高分辨率和良好视觉效果的视频,能够创造出具有丰富细节和自然运动的视频。
- 美学效果:通过将运动和外观信息分开处理,VideoCrafter2 能够在保证视频运动连贯性的同时,提升视频的美学质量,例如清晰度、色彩饱和度和整体视觉效果。
- 概念组合:VideoCrafter2 能够理解和组合复杂的概念,可以生成包含多个现实或虚拟的元素和场景的视频
- 风格和艺术性:VideoCrafter2 可以模拟不同的艺术风格,如赛博朋克、新波普风格等,从而为视频创作提供更多的创意可能性。
VideoCrafter2 的工作原理
VideoCrafter2 的工作原理基于深度学习和扩散模型(Diffusion Models)的原理,通过以下几个关键步骤来实现从文本到视频的生成:
- 数据解耦:VideoCrafter2 将视频内容的生成分解为两个主要部分:运动(motion)和外观(appearance)。运动部分负责视频中物体的移动和动画效果,而外观部分则关注图像的清晰度、颜色和细节。
- 运动学习:使用低质量的视频数据集(如 WebVid-10M)来训练模型的运动部分。这些视频虽然质量不高,但能够提供足够的运动信息,确保生成的视频在运动上是连贯的。
- 外观学习:使用高质量的图像数据集(如 JDB,即 Journey Database,由 Midjourney 生成的图像)来训练模型的外观部分。这些图像具有高分辨率和复杂的概念组合,有助于提升生成视频的视觉质量。
- 模型训练:首先,使用低质量视频和高分辨率图像联合训练一个基础的视频模型。这个模型包含了空间(外观)和时间(运动)两个模块。然后,通过微调空间模块,使用高质量的图像来进一步提升视频的视觉效果。
- 概念组合能力提升:为了增强模型在概念组合方面的能力,VideoCrafter2 使用合成的图像数据集,这些图像包含了复杂的概念组合,帮助模型学习如何将不同的元素和场景融合在一起。
- 生成过程:在训练完成后,VideoCrafter2 可以根据文本提示生成视频。它首先从文本中提取关键信息,然后结合运动和外观的知识,逐步生成每一帧图像,最终拼接成完整的视频序列。
- 评估和优化:通过定量和定性评估,如使用 EvalCrafter 基准测试,来评估生成视频的质量,并根据评估结果进行模型的进一步优化。
如何使用 VideoCrafter2
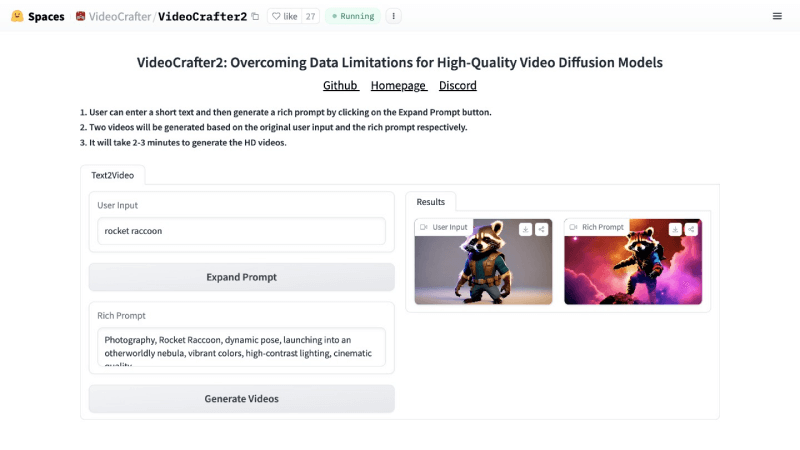
- 访问VideoCrafter2的官方项目主页或VideoCrafter2的Hugging Face空间,然后在 User Input 处输入简短的文本
- 点击 Expand Prompt 按钮生成更加丰富的提示描述
- 然后点击Generate Videos,将分别根据原始用户输入和丰富后的提示生成两个视频
- 生成高清视频需要2-3分钟。
© 版权声明
文章版权归作者所有,未经允许请勿转载。