VideoPoet是什么
VideoPoet是由谷歌的研究团队开发的一种基于大模型的AI视频生成方案,支持从文本、图像或视频输入中合成高质量的视频内容,并生成匹配的音频。VideoPoet的核心优势在于其多模态大模型的设计,可以处理和转换不同类型的输入信号,无需特定数据集或扩散模型,就能够实现多种风格和动作的视频输出,支持生成时长10秒的视频。
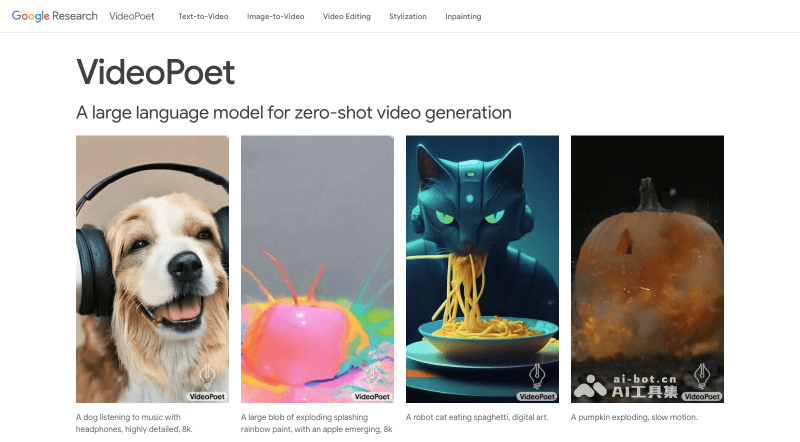
VideoPoet的官网入口
VideoPoet的主要功能
- 文本到视频转换:VideoPoet能够根据文本描述生成相应的视频内容。用户可以输入一段描述,然后模型便会生成与描述相符的视频片段。
- 图像到视频动画:除了文本,VideoPoet还可以根据静态图像生成动画。例如,用户可以上传一张图片,然后模型会将其转换成动态的视频。
- 视频风格化:VideoPoet能够改变现有视频的风格,如将视频转换成油画风格、卡通风格或其他艺术形式。
- 视频编辑和扩展:模型支持对视频进行编辑,如改变视频中物体的动作或添加新的元素。此外,它还能够扩展视频内容,生成更长的视频片段。
- 视频到音频转换:VideoPoet 还可以从视频中生成音频,意味着它可以为无声视频配上音效或音乐。
- 多模态学习:VideoPoet 支持跨模态学习,能够在视频、图像、音频和文本之间进行学习和转换,实现更复杂的创作任务。
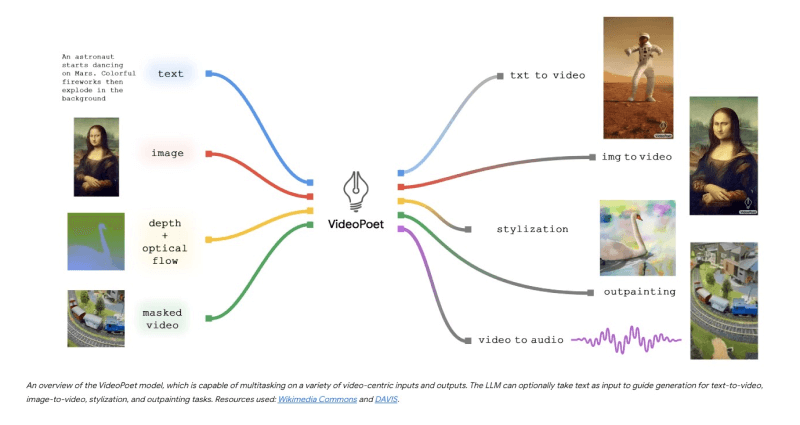
VideoPoet的技术原理
- 多模态输入处理:VideoPoet能够接收和处理不同类型的输入信号,如图像、视频帧、文本和音频波形。这些输入通过特定的分词器(tokenizers)转换为离散的标记(tokens),然后被模型处理。
- 解码器架构:VideoPoet采用了解码器(decoder-only)的Transformer架构。该架构通常用于自然语言处理(NLP)任务,但在VideoPoet中被扩展到视频生成任务。解码器能够根据输入的标记序列预测输出序列,这在视频生成中意味着能够生成连续的视频帧。
- 预训练与任务适应:VideoPoet的训练分为两个阶段。在预训练阶段,模型通过多种多模态生成目标在自回归变换器框架内进行训练。这为模型提供了一个强大的基础,可以适应各种视频生成任务。在任务适应阶段,预训练的模型可以进一步微调,以提高特定任务的生成质量或执行新任务。
- 多模态词汇表:为了处理不同类型的输入,VideoPoet构建了一个统一的多模态词汇表。这个词汇表包含了图像、视频和音频的标记,使得模型能够理解和生成跨模态内容。
- 自回归生成:VideoPoet在生成视频时采用自回归方法,这意味着模型在生成每一帧时都会考虑到之前所有帧的信息。这种方法有助于保持视频内容的连贯性和一致性。
- 超分辨率模块:为了提高视频输出的分辨率和质量,VideoPoet引入了一个专门的空间超分辨率(SR)变换器模块。这个模块在语言模型输出的基础上工作,通过局部窗口注意力机制来提高计算效率,并生成更高分辨率的视频。
- 零样本视频生成:VideoPoet展示了在没有见过特定输入数据分布的情况下处理新文本、图像或视频输入的能力,这被称为零样本视频生成。这表明模型具有很强的泛化能力。
- 任务链式处理:由于VideoPoet在预训练阶段学习了多种任务,它能够将这些任务链式组合起来,执行新的、在训练中未明确教授的任务,如视频编辑和风格化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。