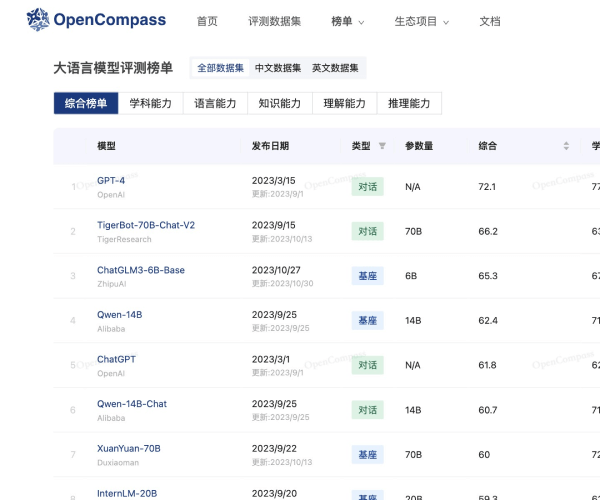
OpenCompass是由上海人工智能实验室(上海AI实验室)于2023年8月正式推出的大模型开放评测体系,通过完整开源可复现的评测框架,支持大语言模型、多模态模型各类模型的一站式评测...
OpenCompass是由上海人工智能实验室(上海AI实验室)于2023年8月正式推出的大模型开放评测体系,通过完整开源可复现的评测框架,支持大语言模型、多模态模型各类模型的一站式评测,并定期公布评测结果榜单。
Open LLM Leaderboard 是最大的大模型和数据集社区 HuggingFace 推出的开源大模型排行榜单,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI语言模型评估框架)封装。
C-Eval是一个适用于大语言模型的多层次多学科中文评估套件,由上海交通大学、清华大学和爱丁堡大学研究人员在2023年5月份联合推出,包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,用以评测大模型中文理解能力。
LLMEval是由复旦大学NLP实验室推出的大模型评测基准,最新的LLMEval-3聚焦于专业知识能力评测,涵盖哲学、经济学、法学、教育学、文学、历史学、理学、工学、农学、医学、军事学、管理学、艺术学等教育部划定的13个学科门类、50余个二级学科,共计约20W道标准生成式问答题目。
PubMedQA是一个生物医学研究问答数据集,包含了1K专家标注,61.2K 个未标注和 211.3K 个人工生成的QA实例,该排行榜目前已收录18个模型的医学测试得分。
H2O EvalGPT 是 H2O.ai 用于评估和比较 LLM 大模型的开放工具,它提供了一个平台来了解模型在大量任务和基准测试中的性能。无论你是想使用大模型自动化工作流程或任务,H2O EvalGPT 都可以提供流行、开源、高性能大模型的详细排行榜,帮助你为项目选择最有效的模型完成具体任务。
Chatbot Arena是一个大型语言模型 (LLM) 的基准平台,以众包方式进行匿名随机对战,该项目方LMSYS Org是由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立的研究组织。