LayerDiffusion是什么
LayerDiffusion(现已更名为LayerDiffuse)是由来自斯坦福大学的研究人员 Lvmin Zhang(即ControlNet的作者张吕敏)和 Maneesh Agrawala 共同提出的一种利用大规模预训练的潜在扩散模型(如Stable Diffusion)生成透明图像的技术,可以帮助用户生成单个透明图像或多个透明图层。该方法的核心在于引入了“潜在透明度”的概念,将图像的alpha通道的透明度信息编码到潜在空间中,从而使得原本用于生成非透明图像的模型能够生成具有透明度的图像。
借助LayerDiffusion,用户无需先生成图片再利用如Remove.bg之类的AI技术进行抠图,可以直接快速生成背景透明的免抠图片。

LayerDiffusion的官网入口
- GitHub代码库:https://github.com/layerdiffusion/LayerDiffusion(模型和源码即将上线)
- LayerDiffusion SD WebUI版:https://github.com/layerdiffusion/sd-forge-layerdiffusion
- arXiv研究论文:https://arxiv.org/abs/2402.17113
LayerDiffusion的功能特性
- 生成透明图像:LayerDiffusio 能够生成具有透明度的图像,这意味着它可以创建具有 alpha 通道的图像,其中 alpha 通道定义了图像中每个像素的透明度。
- 生成多个透明图层:除了单个透明图像,LayerDiffusion还能够生成多个透明图层。这些图层可以独立生成,也可以根据特定的条件(如前景或背景)生成,并且可以混合在一起以创建复杂的场景。
- 条件控制生成:LayerDiffusion 支持条件控制生成,根据透明图像生成前景或背景,为创建特定场景的图像提供了灵活性。
- 图层内容结构控制:用户还可以将 LayerDiffusion 与 ControlNet 控制框架相结合,对图层内容进行结构控制,以指导图层、布局、元素和对象形状等。
- 重复迭代组合图层:LayerDiffusion可以通过重复背景条件前景模型来迭代地组合多个层,以增量地构建具有任意数量的透明图层的组合图像。
- 高质量的图像输出:通过将透明度作为潜在偏移量添加到预训练模型的潜在空间中,LayerDiffusion 能够在不显著改变原始潜在分布的情况下,保持预训练模型的高质量输出。
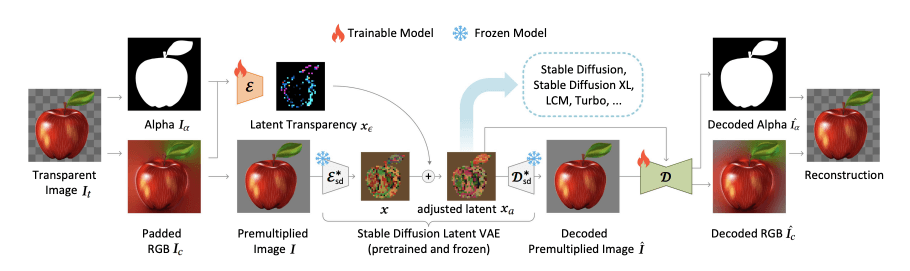
LayerDiffusion的工作原理
- 潜在空间的准备:
- 首先,LayerDiffusion 使用预训练的潜在扩散模型(如 Stable Diffusion)的潜在空间,该潜在空间是通过变分自编码器(VAE)将 RGB 图像编码得到的。
- 为了支持透明度,LayerDiffusion 在潜在空间中引入了一个额外的维度(潜在透明度),用于表示图像的 alpha 通道(透明度信息)。
- 潜在透明度的编码和解码:
- LayerDiffusion 训练两个独立的神经网络:一个潜在透明度编码器和一个潜在透明度解码器。
- 编码器接收原始图像的 RGB 和 alpha 通道,并将透明度信息编码为一个潜在偏移量,这个偏移量被添加到潜在空间的表示中。
- 解码器则从调整后的潜在表示中提取透明度信息,并将其解码回原始的 alpha 通道。

- 潜在空间的调整:
- 为了确保添加的透明度信息不会破坏原始潜在空间的分布,LayerDiffusion通过潜在偏移量来调整潜在表示。
- 这个过程涉及到一个“无害性”度量,即通过比较原始预训练模型的解码器对调整后潜在表示的解码结果,来评估潜在偏移量是否对模型的重建能力造成了破坏。
- 扩散模型的微调:
- 在潜在空间中引入透明度信息后,LayerDiffusion对原始的扩散模型进行微调,使其能够在新的潜在空间中生成透明图像。
- 这个过程涉及到训练扩散模型,使其能够学习如何在添加噪声的过程中保留透明度信息。
- 多图层生成:
- LayerDiffusion 还扩展了其能力,以支持生成多个透明图层。这是通过共享注意力机制和低秩适应(LoRAs)来实现的,确保不同图层之间的一致性和和谐混合。
- 数据集的准备和训练:
- 为了训练模型,研究者们收集了大量透明图像(由 100 万张透明图像组成,涵盖多种内容主题和风格),这些数据通过人类参与的收集方案获得。基于该数据集,模型被训练以生成高质量的透明图像和图层。
© 版权声明
文章版权归作者所有,未经允许请勿转载。