Stable Video 3D是什么
Stable Video 3D(简称SV3D)是由Stability AI公司开发的一个多视角合成和3D生成模型,能够从单张图片生成一致的多视角图像,并进一步优化生成高质量的3D网格模型。该模型在之前发布的Stable Video Diffusion模型的基础上进行了改进,提供了更好的质量和多视角体验。相较于其他的3D生成模型,SV3D的主要优势在于其使用视频扩散模型而不是图像扩散模型,这在生成输出的泛化性和视角一致性方面提供了显著的好处。
Stable Video 3D的功能特性
- 多视角视频生成:SV3D能够从单张图片输入生成多个视角的视频内容。用户可以从不同的方向和角度查看对象,每个视角都是高质量的,并且保持了视角之间的一致性。
- 3D网格创建:通过使用生成的多视角视频和Stable Video 3D模型,用户可以创建对象的3D网格。这些3D网格是从二维图像中推断出来的,可以用于各种3D应用,如游戏开发、虚拟现实、增强现实等。
- 轨道视频生成:Stable Video 3D提供了生成围绕对象的轨道视频的能力,允许用户创建围绕对象旋转或移动的视频,提供了一种动态的视角体验。
- 相机路径控制:SV3D支持沿着指定的相机路径创建3D视频,用户可以精确控制视频的视角和相机运动,为创作提供了更高的自由度。
- 新视角合成(NVS):SV3D在新视角合成方面取得了显著进展,能够从任何给定的角度生成一致且逼真的视图,提高了3D生成的真实感和准确性。
Stable Video 3D的官网入口
- 官方项目主页:https://sv3d.github.io/
- 技术报告:https://stability.ai/s/SV3D_report.pdf
- Hugging Face模型:https://huggingface.co/stabilityai/sv3d
Stable Video 3D的工作原理
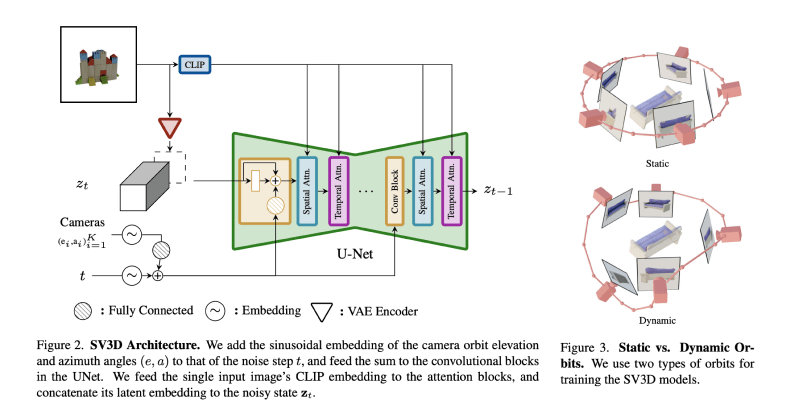
- 新视角合成(NVS):
- 输入图像:用户提供的单张2D图像作为输入,该图像包含一个或多个对象。
- 相机姿态控制:定义一个相机轨迹,包括一系列的角度(仰角和方位角),用于控制生成图像的视角。
- 潜在视频扩散模型:使用一个训练有素的潜在视频扩散模型(如Stable Video Diffusion – SVD),该模型能够根据输入图像和相机姿态生成一系列新的视角图像。这些图像模拟了围绕3D对象的轨道视频。
- 3D表示优化:
- 粗略3D重建:使用生成的多视角图像作为目标,通过训练一个NeRF(Neural Radiance Fields)模型来重建3D对象的粗略表示。这个步骤在较低分辨率下进行,以捕捉对象的大致形状和纹理。
- 网格提取:从训练好的NeRF模型中提取一个初步的3D网格,通常使用Marching Cubes算法。
- 精细优化:采用DMTet(Deep Marching Tetrahedra)表示来进一步细化3D网格,这个步骤在高分辨率下进行,以提高细节的准确性和网格的质量。
- 改进的3D优化技术:
- 掩蔽分数蒸馏采样(SDS)损失:为了提高不可见区域的3D质量,SV3D引入了一种掩蔽分数蒸馏采样损失。这种损失函数专注于在训练过程中填充和优化那些在参考视角中不可见的区域。
- 解耦照明模型:SV3D还提出了一种解耦照明模型,该模型独立于3D形状和纹理进行优化,以减少由于固定照明条件导致的渲染问题。
- 训练和评估:
- 数据集:SV3D在包含多样化3D对象的数据集上进行训练,如Objaverse数据集。
- 评估:通过与真实世界的3D数据和其他NVS方法的比较,评估SV3D生成的多视角图像和3D网格的质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。