VoiceCraft是什么
VoiceCraft是一个由德克萨斯大学奥斯汀分校研究团队开源的神经编解码器语言模型,专注于零样本语音编辑和文本到语音(TTS)任务。该模型采用Transformer架构,通过创新的token重排过程,结合因果掩蔽和延迟叠加技术,可零样本实现在现有音频序列内的高效生成。VoiceCraft在多种口音、风格和噪声条件下的语音编辑和TTS任务上展现出卓越性能,生成的语音自然甚至难以与原声区分。

VoiceCraft的官网入口
- 官方项目主页:https://jasonppy.github.io/VoiceCraft_web/
- GitHub源码库:https://github.com/jasonppy/VoiceCraft
- 研究论文:https://jasonppy.github.io/assets/pdfs/VoiceCraft.pdf
VoiceCraft的功能特性
- 语音编辑:VoiceCraft能够在不需要针对性训练的情况下,对现有的语音录音进行编辑,如插入、删除或替换其中的词语,而编辑后的语音听起来自然,与原录音难以区分。
- 文本到语音转换:该模型能够仅根据文本和简短的声音样本,生成与目标声音相似的语音,无需在训练过程中接触过目标声音。
- 高质量语音合成:VoiceCraft在合成语音时,能够保持语音的自然度和清晰度,使得合成语音在听觉上与真实人声相近。
- 多样化数据适应性:模型在多种口音、说话风格、录音条件以及背景噪音和音乐的挑战性数据集上进行了评估,显示出良好的适应性和一致的性能。
VoiceCraft的工作原理
- 神经编解码器架构:VoiceCraft采用了Transformer架构,一种依赖于自注意力机制的深度学习模型,能够处理序列数据并捕捉序列中的长距离依赖关系。Transformer架构在自然语言处理(NLP)领域已经证明了其高效性,VoiceCraft将其应用于语音信号的处理。
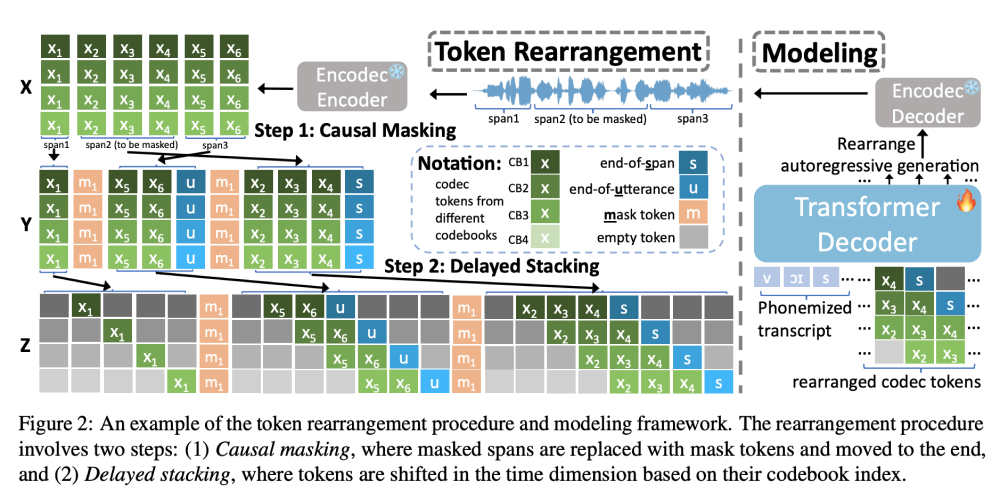
- Token重排过程:VoiceCraft引入了一种特殊的token重排过程,该过程包括两个主要步骤——因果掩蔽和延迟叠加。这个过程允许模型在生成语音时考虑到前后文信息,从而生成更加自然和连贯的语音序列。

- 因果掩蔽:这一步骤涉及将输入语音信号量化为一系列编码器token,并将这些token按照因果关系(即不影响未来输出)进行掩蔽。这意味着模型在预测被掩蔽的token时,只能依赖于未被掩蔽的token。
- 延迟叠加:在因果掩蔽的基础上,延迟叠加步骤进一步调整了编码器token的时间维度,以确保模型在预测当前时间步的编码器token时,能够有效地利用之前时间步的信息。
- 自回归序列预测:VoiceCraft在训练和推理过程中使用自回归序列预测方法。这意味着模型会一次生成一个token,并在每个时间步使用之前生成的所有token作为上下文信息来预测下一个token。
- 多码本建模:为了提高效率和生成质量,VoiceCraft使用了残差向量量化(RVQ)技术,将语音信号编码为多个码本的序列。这些码本捕捉了语音的不同特征,使得模型能够更精细地建模语音信号。
- 推理和生成:在推理阶段,VoiceCraft根据输入的文本和音频信息(对于零样本TTS任务,还包括目标声音的简短参考录音),自回归地生成对应的语音序列。对于语音编辑任务,模型会根据原始音频和编辑后的文本目标,生成与目标文本匹配的语音,同时保持未编辑部分的原始特征。
VoiceCraft的应用场景
- 有声读物制作:VoiceCraft可以用来创建高质量的有声读物,通过生成自然流畅的语音来讲述故事或书籍内容,为听众提供沉浸式的听觉体验。
- 视频内容创作:在互联网视频制作中,VoiceCraft可以用于快速生成旁白或角色对话,特别是在动画、教育视频或广告中,可以节省配音成本并提高制作效率。
- 播客音频编辑:对于播客制作者,VoiceCraft提供了强大的音频编辑工具,可以轻松修正错误或更改内容,而无需重新录制整个播客,从而加快内容发布流程。
- 多语言内容生产:VoiceCraft的跨语言能力使其能够为不同语言的听众生成内容,有助于跨越语言障碍,实现全球化的内容分发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。