Champ是什么
Champ是由阿里巴巴、复旦大学和南京大学的研究人员共同提出的一种基于3D的将人物图片转换为视频动画的模型,该方法结合了3D参数化模型(特别是SMPL模型)和潜在扩散模型,能够精确地捕捉和再现人体的3D形状和动态,同时保持动画的时间一致性和视觉真实性,以生成高质量的人类动画视频。
Champ的官网入口
- 官方项目主页:https://fudan-generative-vision.github.io/champ/#/
- GitHub源码库:https://github.com/fudan-generative-vision/champ
- arXiv研究论文:https://arxiv.org/abs/2403.14781
Champ的功能特性
- 人物图片转视频动画:Champ可以将静态人物图片转换为动态视频动画,通过精确捕捉和再现人体的形状和动作,创造出既真实又可控的动态视觉内容。
- 3D形状和姿势表示:Champ能够精确地表示和控制人体的形状和姿势,可从源视频中提取的人体几何和运动特征更加准确。
- 跨身份动画生成:Champ能够将来自一个视频的运动序列应用到另一个不同身份的参考图像上,实现跨身份的动画生成。
- 高质量的视频生成:Champ在生成视频时保持了角色和背景之间的一致性,同时通过时间对齐模块确保帧之间的流畅过渡,从而产生高质量的视频输出。
- 与T2I文生图模型结合:结合根据文本描述生成图像的T2I文生图模型,用户可以通过文本描述指定动画中的角色外观和动作,然后Champ根据这些描述再生成动画视频。
Champ的工作原理
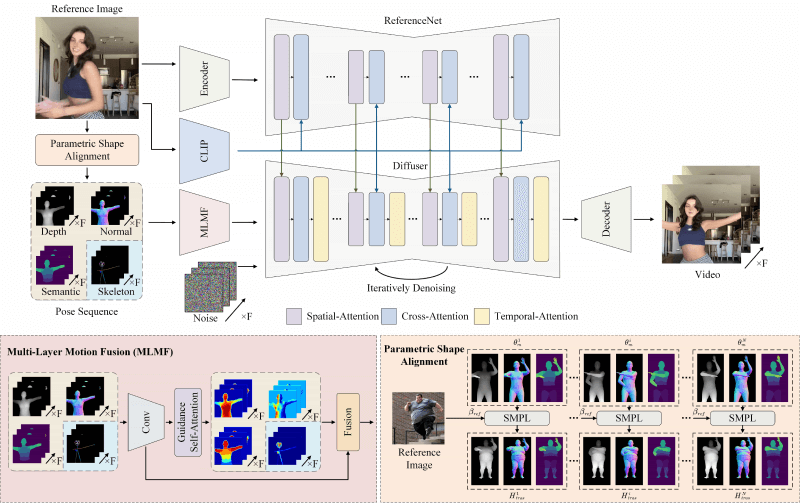
- 3D人体参数化模型(SMPL):
- 使用SMPL模型来表示人体的形状和姿势。SMPL模型是一个基于参数的3D人体模型,能够捕捉人体的形状变化和姿势变化。
- 通过将SMPL模型拟合到参考图像上,可以获取人体的形状参数和姿势参数。
- 从源视频中提取运动:
- 利用现有的框架(如4D-Humans)从源视频中提取人体的运动序列。这些运动序列包括连续的SMPL模型参数,用于描述视频中人物的动作。
- 生成深度、法线和语义图:
- 将SMPL模型渲染成深度图、法线图和语义图,这些图像包含了3D结构、表面方向和人体部位的详细信息。
- 运动对齐和指导:
- 使用提取的SMPL模型参数来对齐参考图像中的人物形状和姿势,确保动画中的人物与源视频中的人物动作一致。
- 引入基于骨架的运动指导,以增强对复杂运动(如面部表情和手指动作)的表示。
- 多层运动融合:
- 通过自注意力机制,将深度、法线、语义和骨架信息的特征图进行融合,以生成一个综合的运动指导信号。
- 潜在扩散模型:
- 利用潜在扩散模型(如Latent Diffusion Model)作为生成框架,将上述运动指导信号和参考图像编码后的特征结合起来,生成动画帧。
- 在潜在空间中应用去噪过程,逐步从带有噪声的表示中恢复出清晰的动画帧。
- 训练和推理:
- 在训练阶段,模型学习如何根据给定的参考图像和运动指导生成连贯的动画序列。
- 在推理阶段,模型根据新的参考图像和运动序列生成动画,展示出其泛化能力。
- 视频生成:
- 将生成的帧序列组合成视频,同时确保视频中的人物与参考图像在视觉上保持一致,且动作流畅自然。
© 版权声明
文章版权归作者所有,未经允许请勿转载。