CogVLM2是什么
CogVLM2是由智谱AI推出的新一代多模态大模型,在视觉和语言理解方面实现了显著的性能提升,支持高达8K的文本长度和1344*1344分辨率的图像输入,具备强大的文档图像理解能力。该模型采用50亿参数的视觉编码器与70亿参数的视觉专家模块,通过深度融合策略,优化了视觉与语言模态的交互,确保了在增强视觉理解的同时,语言处理能力也得到保持。CogVLM2的开源版本支持中英文双语,模型大小为19亿参数,但实际推理时激活的参数量约为120亿,展现了在多模态任务中的高效性能。

CogVLM2的改进点
CogVLM2模型相比前代的改进点主要包括以下几个方面:
- 性能提升:在OCRbench和TextVQA等多个关键基准测试上,CogVLM2的性能有了显著提升,例如在OCRbench上性能提升了32%,在TextVQA上性能提升了21.9%。
- 文档图像理解:CogVLM2增强了对文档图像的理解和问答能力,特别是在DocVQA基准测试中表现出色。
- 支持高分辨率图像:模型支持高达1344*1344像素的图像分辨率,能够处理更高清晰度的图像。
- 支持长文本:CogVLM2支持长达8K的文本输入,这使得模型能够处理更长的文档和更复杂的语言任务。
- 双语支持:CogVLM2提供了支持中英文双语的开源模型版本,增强了模型的多语言能力。
CogVLM2的模型信息
CogVLM2开源了两款以Meta-Llama-3-8B-Instruct为语言基座模型的CogVLM2,分别是cogvlm2-llama3-chat-19B和cogvlm2-llama3-chinese-chat-19B,感兴趣的用户可以前往GitHub、Hugging Face或魔搭社区进行下载或在线体验。
|
模型名称
|
cogvlm2-llama3-chat-19B
|
cogvlm2-llama3-chinese-chat-19B
|
|
基座模型
|
Meta-Llama-3-8B-Instruct
|
Meta-Llama-3-8B-Instruct
|
|
语言
|
英文
|
中文、英文
|
|
模型大小
|
19B
|
19B
|
|
任务
|
图像理解,对话模型
|
图像理解,对话模型
|
|
模型链接
|
||
|
体验链接
|
||
|
Int4模型
|
暂未推出
|
暂未推出
|
|
文本长度
|
8K
|
8K
|
|
图片分辨率
|
1344 * 1344
|
1344 * 1344
|
CogVLM2的模型架构
CogVLM2的模型架构在继承上一代模型的基础上进行了优化和创新,具体特点如下:
- 视觉编码器:CogVLM2采用了一个拥有50亿参数的视觉编码器,负责对输入图像进行特征提取和编码。
- 视觉专家模块:在大语言模型中整合了一个70亿参数的视觉专家模块,这一模块通过独特的参数设置,精细地建模了视觉与语言序列的交互。
- 深度融合策略:CogVLM2采用了深度融合策略,使得视觉模态与语言模态能够更加紧密地结合,从而增强了模型在视觉理解能力的同时,保持了在语言处理上的优势。
- MLP Adapter:模型中使用了MLP(多层感知器)Adapter,用于调整和适配不同模态之间的特征。
- 降采样模块:为了更好地处理和理解高分辨率的文档或网页图片,CogVLM2在视觉编码器后引入了一个专门的降采样模块,有效提取关键信息,减少输入到语言模型中的序列长度。
- Word Embedding:模型包含了Word Embedding层,用于将文本转换为模型可以理解的数值型向量。
- 多专家模块结构:CogVLM2设计了多专家模块结构,使得在进行推理时,实际激活的参数量仅约120亿,这种设计既保证了模型的性能,又提高了推理效率。
- 语言基座模型:CogVLM2使用了Meta-Llama-3-8B-Instruct作为语言基座模型,为模型提供了强大的语言理解和生成能力。

CogVLM2的模型性能
CogVLM2的团队在一系列多模态基准上进行了定量评估,这些基准包括 TextVQA、DocVQA、ChartQA、OCRbench、MMMU、MMVet、MMBench等。从下表可以看出CogVLM2 的两个模型,尽管具有较小的模型尺寸,但在多个基准中取得 SOTA性能;而在其他性能上,也能达到与闭源模型(例如GPT-4V、Gemini Pro等)接近的水平。
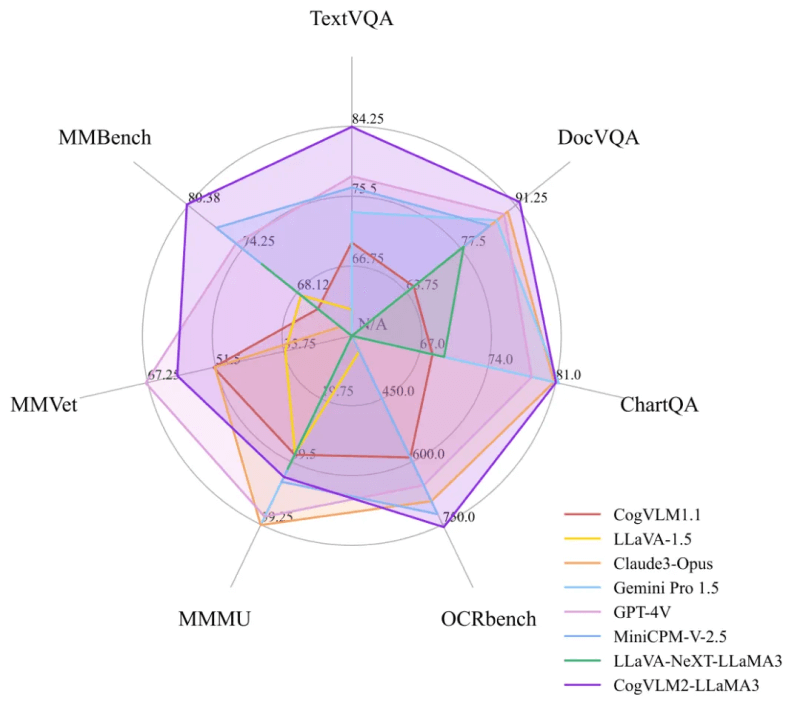
| 模型 | 是否开源 | 模型规模 | TextVQA | DocVQA | ChartQA | OCRbench | MMMU | MMVet | MMBench |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA-1.5 | ✅ | 13B | 61.3 | – | – | 337 | 37.0 | 35.4 | 67.7 |
| Mini-Gemini | ✅ | 34B | 74.1 | – | – | – | 48.0 | 59.3 | 80.6 |
| LLaVA-NeXT-LLaMA3 | ✅ | 8B | – | 78.2 | 69.5 | – | 41.7 | – | 72.1 |
| LLaVA-NeXT-110B | ✅ | 110B | – | 85.7 | 79.7 | – | 49.1 | – | 80.5 |
| InternVL-1.5 | ✅ | 20B | 80.6 | 90.9 | 83.8 | 720 | 46.8 | 55.4 | 82.3 |
| QwenVL-Plus | ❌ | – | 78.9 | 91.4 | 78.1 | 726 | 51.4 | 55.7 | 67.0 |
| Claude3-Opus | ❌ | – | – | 89.3 | 80.8 | 694 | 59.4 | 51.7 | 63.3 |
| Gemini Pro 1.5 | ❌ | – | 73.5 | 86.5 | 81.3 | – | 58.5 | – | – |
| GPT-4V | ❌ | – | 78.0 | 88.4 | 78.5 | 656 | 56.8 | 67.7 | 75.0 |
| CogVLM1.1 (Ours) | ✅ | 7B | 69.7 | – | 68.3 | 590 | 37.3 | 52.0 | 65.8 |
| CogVLM2-LLaMA3 (Ours) | ✅ | 8B | 84.2 | 92.3 | 81.0 | 756 | 44.3 | 60.4 | 80.5 |
| CogVLM2-LLaMA3-Chinese (Ours) | ✅ | 8B | 85.0 | 88.4 | 74.7 | 780 | 42.8 | 60.5 | 78.9 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。